
介绍
Stable Diffusion是一种深度学习模型,可以文字生图,拥有丰富的插件,具有较强的可控性,其中Web UI的界面更加直观,便于上手

软件及模型下载
秋叶整合包和部分模型:
链接: https://pan.baidu.com/s/1sDF36I4q5O7wh-eXwneXGA
提取码: i42g
常用网址
lightCC:https://lightcc.cloud/
我的邀请码:96RMBN8U9380
土司:https://tusiart.com/
哩布哩布:https://www.liblib.art/
CIVITAI:https://www.civitai.com(需外网)
生图原理
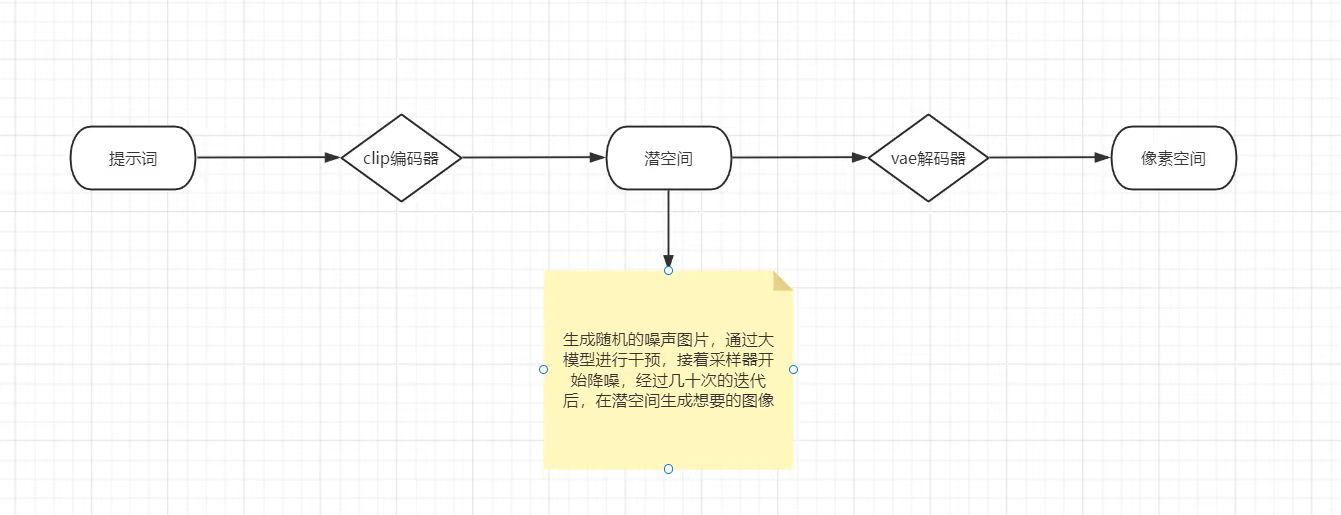
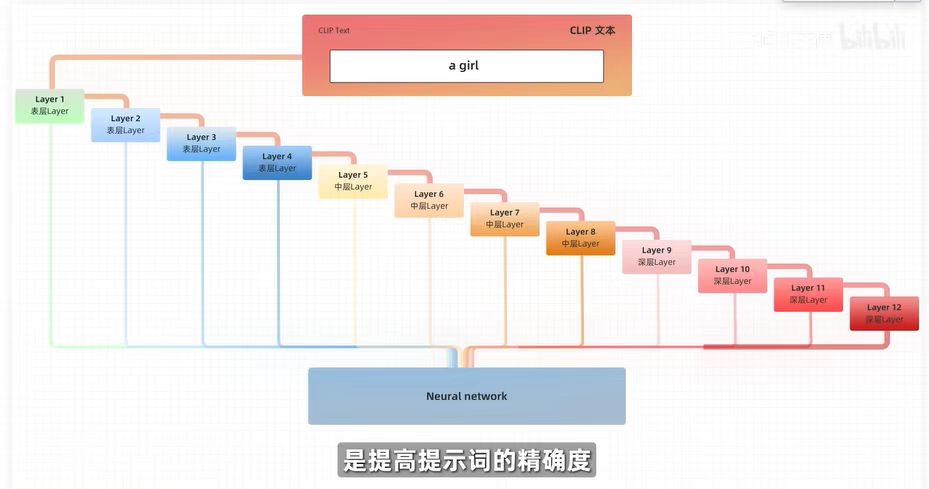
终止层越大,与提示词相关性越低,通常选择2终止层
参数
大模型:Checkpoint
外挂vae模型:左边适合二次元,右边适合写实,可以不使用

迭代步数:重复执行采样去噪的步数,超过一定步数后,质量不会明细提高
随机数种子:-1代表随机,每个图像的种子数是唯一的,可以固定种子值来对某一张图片进行调整
提示词
有本地和在线翻译,提示,历史记录,收藏,设置起手式等功能
会按提示词的顺序构建图片,一次只能理解75个token的词

微调模型
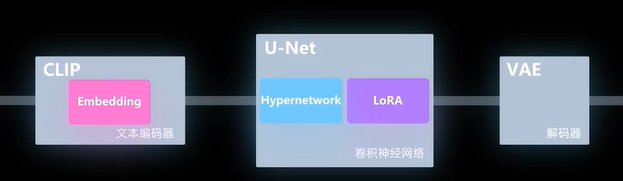
Embedding
嵌入式
自带的几个反向模型:

提示词引导系数:建议4到15之间
Hypernetwork
超网络
需要触发词才能生效
LoRA
低秩效应

有的需要触发词
图生图
参数
尺寸,缩放,重绘幅度(越小越依赖原图,越大越依赖提示词),反推参考图提示词插件
涂鸦
提高重绘幅度(依赖提示词和大模型的想象)
局部重绘
添加蒙版,选择合适的大模型(保证重绘部分和原图风格统一)
修改重绘幅度,重绘一次只修改一个部分的内容(多个内容会让大模型不知道改哪里而出错)
修改蒙版边缘模糊度(过大会增加模糊范围)
处理方式:原版(依原图作为参考)、填充(对蒙版进行模糊处理,再重新迭代生成)、潜空间噪声(在蒙版区域生成新的噪声),空白潜空间(在蒙版处填充纯色,重新生成图像)
重绘区域:决定哪些部分对蒙版区域的重绘产生影响,边缘预留像素对蒙版边缘以外的区域产生影响
重绘非蒙版:反转蒙版区域
柔和重绘:二次重绘,使蒙版边缘融合更好,参数:schedule bias(越大蒙版与参考图融合越强),preservation strength(越小生成内容越偏向大模型和提示词,越大越接近参考图)
涂鸦重绘
有颜色选项和蒙版透明度(降低颜色蒙版的强度)
上传重绘蒙版
上传黑白图片作为蒙版
比如扩充图片时,可以使用ps裁剪扩充画布,蒙版图原图部分填充黑色。
上传扩充后的图片和蒙版图,选择原图的参数和大模型,删掉一些参数(比如扩充背景时,删除掉人物提示词),调整重绘幅度(到一个合适的数值才会生成新的内容,过大则和原图关联变小)
接缝问题(修改重绘区域,边缘模糊度,柔和重绘)
重绘部分可以用白色或简单手绘(PS)一下
批量处理
PNG图片信息,参考图片的文件名和修改图片的文件名要一致
多张参考图需要裁剪成相同尺寸,PNG图片数量和文件名要与参考图一致
高清放大
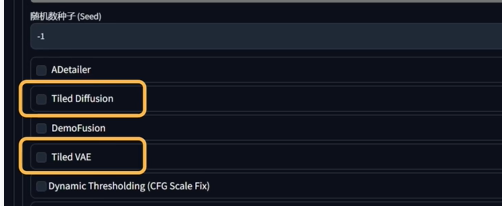
开启高分辨率,设置放大倍数,非常占用显存,设置2倍以上就可能出现显存不足的现象。所以可以使用图生图里的tiled diffusion插件,原理是将原图分割成小块分别扩充
参数设置
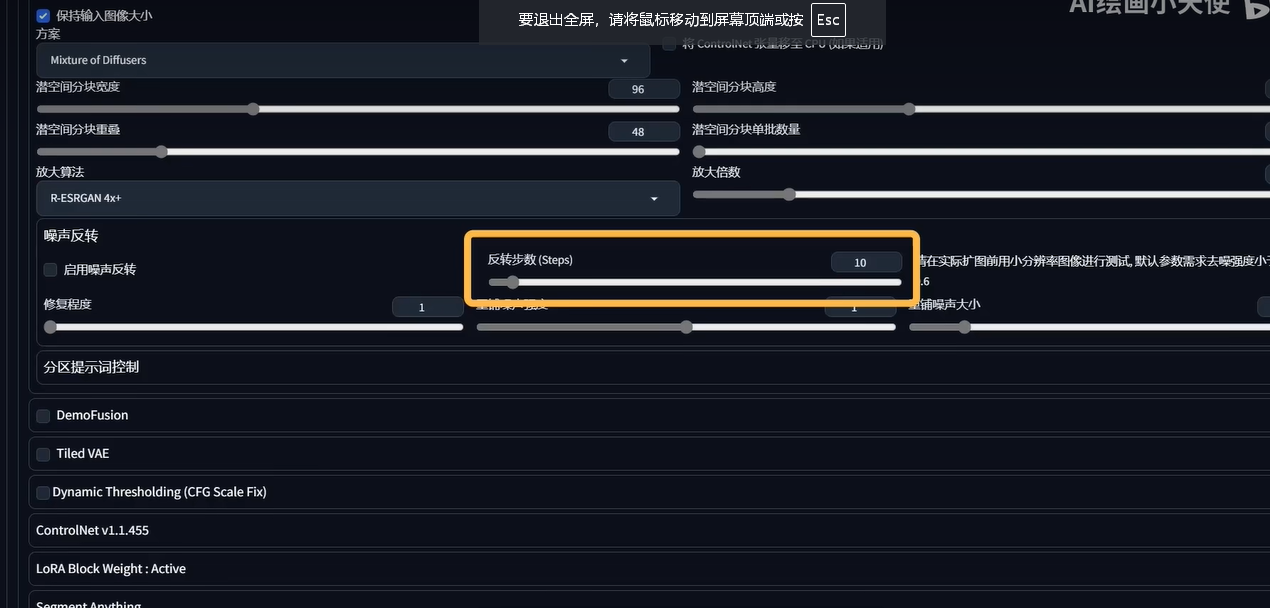
脚本放大
占用更小的显存,速度更快,效果较差
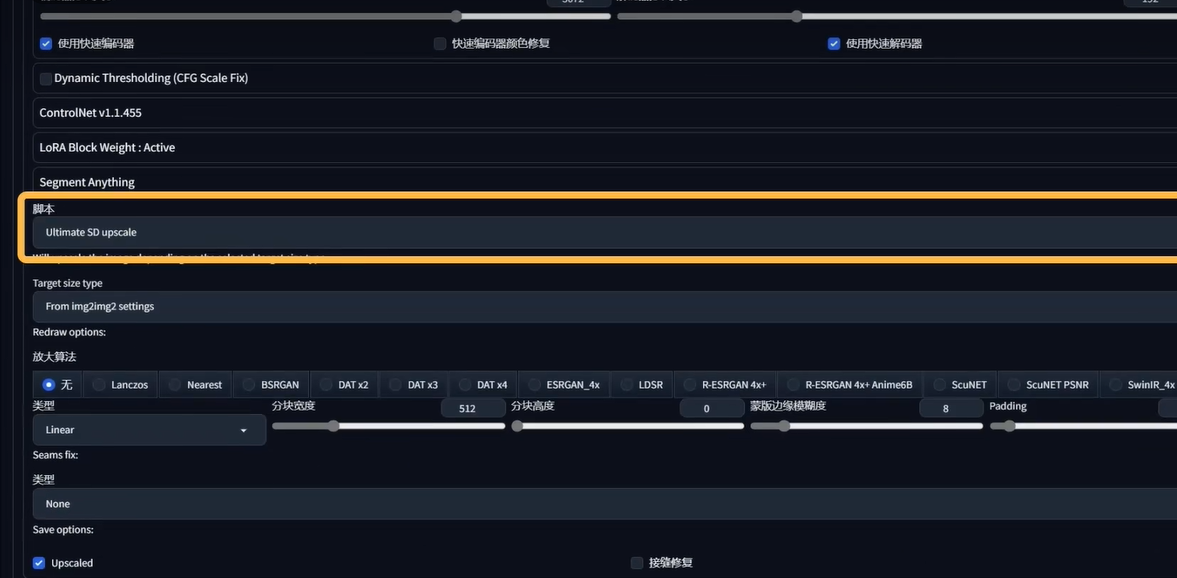
模型融合
融合后的模型也会保存在文件夹中
脚本
XYZ-plot

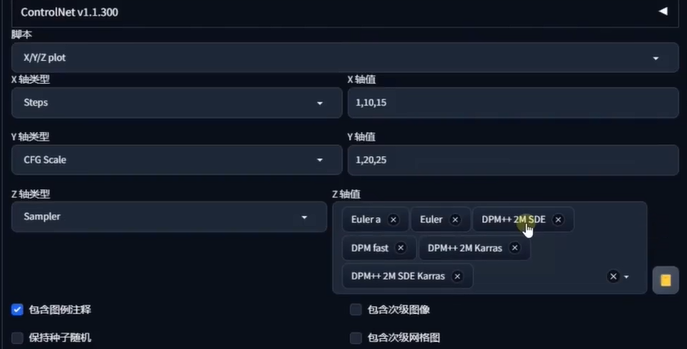
提示词矩阵

图片浏览器
快速查看之前生成的图片